12 Dec 2014
Just a quick post on one of my favorite features of tcpdump that I
have found useful for doing quick investigations of the behavior of an app
and you need a little bit more than what you get with the access logs.
Wireshark has this great site that given a HTTP request,
will give you a filter that if paired with the -A (print packet in ASCII) option from tcpdump
will match all related HTTP traffic that is going on in a node.
A couple of basic examples:
tcpdump -A 'tcp[((tcp[12:1] & 0xf0) >> 2):2] = 0x4745 && tcp[((tcp[12:1] & 0xf0) >> 2) + 2:1] = 0x54'
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wlan0, link-type EN10MB (Ethernet), capture size 65535 bytes
16:31:54.870479 IP 10.0.1.134.56724 > 10.0.7.64.http-alt: Flags [P.], seq 1988783165:1988783563, ack 2609786817, win 65535, options [nop,nop,TS val 703013338 ecr 40647638], length 398
E...Bt@.@...
...
..@....v.l=../............
).!..l;.GET /v2/apps HTTP/1.1
Host: 10.0.77.64:8080
Connection: keep-alive
Accept: application/json, text/javascript, */*; q=0.01
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36
Referer: http://10.0.7.64:8080/
Accept-Encoding: gzip, deflate, sdch
Accept-Language: en-US,en;q=0.8
tcpdump -A 'tcp[((tcp[12:1] & 0xf0) >> 2):4] = 0x504f5354'
tcpdump: verbose output suppressed, use -v or -vv for full protocol decode
listening on wlan0, link-type EN10MB (Ethernet), capture size 65535 bytes
16:41:59.925399 IP 10.0.1.134.56765 > 10.0.7.64.http-alt: Flags [P.], seq 1595944397:1595945056, ack 1073928153, win 65535, options [nop,nop,TS val 703610055 ecr 40792556], length 659
E.....@.@.o.
...
..@...._ -.@..............
).<..nq.POST /v2/apps HTTP/1.1
Host: 10.0.77.64:8080
Connection: keep-alive
Content-Length: 182
Accept: application/json, text/javascript, */*; q=0.01
Origin: http://10.0.7.64:8080
X-Requested-With: XMLHttpRequest
User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.71 Safari/537.36
Content-Type: application/json
Referer: http://10.0.7.64:8080/
Accept-Encoding: gzip, deflate
Accept-Language: en-US,en;q=0.8
You can add more info to the path (e.g. GET /v2/) to narrow down the actions
that are being investigated.
12 Dec 2014
(This is a post for the Emacs Advent Calendar 2014 from Japan, a similar English version can be found here)
Org modeの話を聞いたことがある方は、Org modeは「TODOリスト管理ツールの
一つだ」と思われる方が多いかもしれません。それはその通りですが、
Org Babelというモードで、「文芸的プログラミング(Literate Programming)」を実現することができます。
Org Babelの使い方を示すために、あるホストのモニタリング情報を表示する、
単純なSinatraアプリケーションを例えにします。
例: ホストのモニタリング情報を表示するSinatra app
表示したい項目をシステムの uptime と ESTABLISHEDコネクションの数に絞り込みます。
uptime
20:37 up 4 days, 9:48, 5 users, load averages: 0.67 0.86 1.11
ESTABLISHED コネクションの数:
netstat -an | grep ESTABLISHED | wc -l
5
この二つのコマンドの結果を集めて、 HTTPクライアントを使えば
GET /vars で取れるようになります:
事前準備
まず、ディレクトリの作成が必要です:
mkdir -p org
mkdir -p src
touch readme.org
org/ ディレクトリの下に置くファイルはOrg mode で書きますsrc/ ディレクトリの下に置くファイルはSinatraアプリケーションのソースコード
(readme.org の作成は必要ではないですが、best practiceとしておすすめします…)
最終的に、ディレクトリ構成はこんな感じになります:
.
├── org
│ ├── app.org
│ └── run.org
├── readme.org
├── src
│ ├── Gemfile
│ ├── app.rb
│ └── config.ru
実装
アプリケーションの実装自体は org/app.org に書きます。
touch org/app.org
プロトタイプ
SinatraのWebアプリケーションを実装前に、Org Babel を使ってプロトタイプを作りましょう。
Rubyのcode blockを書いたら、 C-c C-c で実行することができます。
*** Notes on how to get the results
We could use something simple like:
#+begin_src ruby :results output code
s = <<VARS
Uptime:
#{`uptime`}
ESTABLISHED connections:
#{`netstat -an | grep ESTABLISHED | wc -l`}
VARS
puts s
#+end_src
#+RESULTS:
#+BEGIN_SRC ruby
Uptime:
22:23 up 4 days, 11:34, 5 users, load averages: 0.58 0.46 0.30
ESTABLISHED connections:
8
#+END_SRC
:tangle の使い方
:tangle はOrg modeのcode block switch argumentsの一つです。
これを使えば、Org modeのcode blockは実装しているファイルを設定できます。
例えば、 :tangle を使って Gemfile と config.ru の内容を書きましょう。
Dependencies from the app, just sinatra and webrick for the server is ok for now.
#+BEGIN_SRC ruby :tangle src/Gemfile
gem 'sinatra'
#+END_SRC
Needed to start the Sinatra application:
#+BEGIN_SRC ruby :tangle src/config.ru
require './app.rb'
run Sinatra::Application
#+END_SRC
全体例
EmacsのOrg modeバッファーで, C-c C-v t か C-c C-v C-t を叩けば、
Org modeの org-babel-tangle の機能を呼び出します。
これで、動かせるプログラムは src/ ディレクトリの下に現れます。
#+TITLE: Monitoring HTTP endpoint
This is a simple Sinatra application that provides
the following endpoints:
‐ =/= :: which responds =OK= in case all is good with the server.
‐ =/vars= :: to get info about the system
** Bootstrapping the app
*** Gemfile
Dependencies from the app, just sinatra and webrick for now is ok.
#+BEGIN_SRC ruby :tangle src/Gemfile
gem 'sinatra'
#+END_SRC
*** Config.ru
Needed to start the sinatra application
#+BEGIN_SRC ruby :tangle src/config.ru
require './app.rb'
run Sinatra::Application
#+END_SRC
** The App
*** Import dependencies
#+BEGIN_SRC ruby :tangle src/app.rb
require 'sinatra'
#+END_SRC
*** =/= endpoint
Just respond with =OK=.
#+BEGIN_SRC ruby :tangle src/app.rb
get '/' do
'OK'
end
#+END_SRC
*** =/vars= endpoint
Respond with info about the system:
#+BEGIN_SRC ruby :tangle src/app.rb
get '/vars' do
r = <<VARS
Uptime:
#{`uptime`}
ESTABLISHED connections:
#{`netstat -an | grep ESTABLISHED | wc -l`}
VARS
r
end
#+END_SRC
動かす方法
次に、プログラムを動かす方法を org/run.org にまとめます。
プログラムを動かす前に、Sinatraのプログラムに修正があったかも知れないので、
#+include: org/app.org でこの依存関係を設定します。
#+TITLE: Running the Application
#+include: "org/app.org"
** Run it
To run it, we will need to get the dependencies first,
and then start it with bundler:
#+name: server
#+BEGIN_SRC sh :dir src
bundle install
bundle exec rackup
#+END_SRC
Now let's send some requests to it:
#+name: curl
#+BEGIN_SRC sh :wait 1
while true; do
curl 127.0.0.1:9292/vars 2> /dev/null
sleep 1
done
#+END_SRC
Emacsでlong running processesを実行できますが、そうするとEmacsがコードブロック
の結果待ちをしてしまいます… それを避けるため、
コードブロックの上に、 #+name を設定すれば、私が作ったgemで叩くことができます:
gem install org-converge
org-run org/run.org
そうすると結果は以下のようになります:
org-run org/run.org
...
Running code blocks now! (2 runnable blocks found in total)
server -- started with pid 71840
curl -- started with pid 71841
server -- Using rack 1.5.2
server -- Using rack-protection 1.5.3
server -- Using tilt 1.4.1
server -- Using sinatra 1.4.5
server -- Using bundler 1.7.1
server -- Your bundle is complete!
server -- Use `bundle show [gemname]` to see where a bundled gem is installed.
server -- [2014-12-11 22:56:42] INFO WEBrick 1.3.1
server -- [2014-12-11 22:56:42] INFO ruby 2.1.2 (2014-05-08) [x86_64-darwin11.0]
server -- [2014-12-11 22:56:42] INFO WEBrick::HTTPServer#start: pid=71848 port=9292
server -- 127.0.0.1 - - [11/Dec/2014 22:56:42] "GET /vars HTTP/1.1" 200 110 0.0527
curl -- Uptime:
curl -- 22:56 up 4 days, 12:07, 5 users, load averages: 0.78 0.84 0.76
curl --
curl --
curl -- ESTABLISHED connections:
curl -- 12
curl --
curl --
server -- 127.0.0.1 - - [11/Dec/2014 22:56:43] "GET /vars HTTP/1.1" 200 110 0.0210
curl -- Uptime:
curl -- 22:56 up 4 days, 12:07, 5 users, load averages: 0.78 0.84 0.76
curl --
curl --
curl -- ESTABLISHED connections:
curl -- 12
curl --
curl --
まとめ
Org modeはとても便利です!皆さんぜひお試しください。
しかも、Githubさんが org-rubyを使って .org ファイルをHTMLに変換してくれるのです。
Ruby の Org modeパーサはまだOrg mode のすべての機能に追いついていませんが、
私がある程度メンテナンスしています。もしOrg Rubyに何かの問題があれば、
こちらに issue を発行していただければと思います。 :)
(そして、日本語が間違っている場合、こちらに PR ください…)
12 Dec 2014
Most people that have heard about Org mode are aware that
it is a tool meant for creating TODO lists, taking notes,
and even doing documentation to some extent.
What is not immediately clear about Org mode is that it is a very
powerful tool for doing literate programming and a comfortable
environment for working with active documents.
Rather than explain the ideas one by one, I will give a more
practical example of what it is possible to do with it.
Example: Creating a monitoring HTTP endpoint
Let’s create a simple HTTP endpoint with Sinatra which
will respond with some information about the host where it is running,
like its uptime and the number of established connections.
Requirements
What we want is basically the output of the following commands:
…which will show something like this:
20:37 up 4 days, 9:48, 5 users, load averages: 0.67 0.86 1.11
And:
netstat -an | grep ESTABLISHED | wc -l
which shows a number:
The result from both commands would be aggregated into
the response sent by the the server when we request /vars:
Result:
Uptime:
20:37 up 4 days, 9:48, 5 users, load averages: 0.67 0.86 1.11
ESTABLISHED connections: 14
Preparation
We will start by creating a couple of folders, one for the content
we write in Org, and another one for the actual implementation.
mkdir -p org
mkdir -p src
touch readme.org
(The readme.org file is of course optional, but still a good practice to follow.)
In the end, our directory structure will look something like this:
.
├── org
│ ├── app.org
│ └── run.org
├── readme.org
├── src
│ ├── Gemfile
│ ├── app.rb
│ └── config.ru
Implementation
Most of the contents of our application, we will develop within an
org/app.org file.
touch org/app.org
Prototyping phase
Usually, while developing a program we go into a REPL to test out what
would eventually make it into the program.
With Org Babel though, it is possible to call the code blocks within
an Emacs buffer, so we can actually start prototyping using Org mode.
Each time we press C-c C-c on top of the code block, the results
would be refreshed:
*** Notes on how to get the results
We could use something simple like:
#+begin_src ruby :results output code
s = <<VARS
Uptime:
#{`uptime`}
ESTABLISHED connections:
#{`netstat -an | grep ESTABLISHED | wc -l`}
VARS
puts s
#+end_src
#+RESULTS:
#+BEGIN_SRC ruby
Uptime:
22:23 up 4 days, 11:34, 5 users, load averages: 0.58 0.46 0.30
ESTABLISHED connections:
8
#+END_SRC
Using :tangle to create the files of the program
We can have a code block be tangled into a file by using the
:tangle switch argument. For example, we can define the Gemfile
and config.ru files within an Org mode buffer like this:
Dependencies from the app, just sinatra and webrick for the server is ok for now.
#+BEGIN_SRC ruby :tangle src/Gemfile
gem 'sinatra'
#+END_SRC
Needed to start the Sinatra application:
#+BEGIN_SRC ruby :tangle src/config.ru
require './app.rb'
run Sinatra::Application
#+END_SRC
Full example
The Sinatra application would then look something like this.
From Emacs, we can either press C-c C-v t or C-c C-v C-t,
(M-x org-babel-tangle also does it) to tangle the web of
code blocks to their respective files.
#+TITLE: Monitoring HTTP endpoint
This is a simple Sinatra application that provides
the following endpoints:
‐ =/= :: which responds =OK= in case all is good with the server.
‐ =/vars= :: to get info about the system
** Bootstrapping the app
*** Gemfile
Dependencies from the app, just sinatra and webrick for now is ok.
#+BEGIN_SRC ruby :tangle src/Gemfile
gem 'sinatra'
#+END_SRC
*** Config.ru
Needed to start the sinatra application
#+BEGIN_SRC ruby :tangle src/config.ru
require './app.rb'
run Sinatra::Application
#+END_SRC
** The App
*** Import dependencies
#+BEGIN_SRC ruby :tangle src/app.rb
require 'sinatra'
#+END_SRC
*** =/= endpoint
Just respond with =OK=.
#+BEGIN_SRC ruby :tangle src/app.rb
get '/' do
'OK'
end
#+END_SRC
*** =/vars= endpoint
Respond with info about the system:
#+BEGIN_SRC ruby :tangle src/app.rb
get '/vars' do
r = <<VARS
Uptime:
#{`uptime`}
ESTABLISHED connections:
#{`netstat -an | grep ESTABLISHED | wc -l`}
VARS
r
end
#+END_SRC
Running it
Now that, we have defined the program, it would be also helpful to
define how to actually run it. We will write this in a org/run.org
file.
Note how we are including the org/app.org application as a
dependency so that in case of changes those code blocks become tangled
as well.
#+TITLE: Running the Application
#+include: "org/app.org"
** Run it
To run it, we will need to get the dependencies first,
and then start it with bundler:
#+name: server
#+BEGIN_SRC sh :dir src
bundle install
bundle exec rackup
#+END_SRC
Now let's send some requests to it:
#+name: curl
#+BEGIN_SRC sh :wait 1
while true; do
curl 127.0.0.1:9292/vars 2> /dev/null
sleep 1
done
#+END_SRC
Here we are giving the code block a #+name:, doing this make it
possible to reuse the code block later on. I made a small gem that
makes it possible to run these kind of blocks when they have a name.
gem install org-converge
org-run org/run.org
The output would look like this:
org-run org/run.org
...
Running code blocks now! (2 runnable blocks found in total)
server -- started with pid 71840
curl -- started with pid 71841
server -- Using rack 1.5.2
server -- Using rack-protection 1.5.3
server -- Using tilt 1.4.1
server -- Using sinatra 1.4.5
server -- Using bundler 1.7.1
server -- Your bundle is complete!
server -- Use `bundle show [gemname]` to see where a bundled gem is installed.
server -- [2014-12-11 22:56:42] INFO WEBrick 1.3.1
server -- [2014-12-11 22:56:42] INFO ruby 2.1.2 (2014-05-08) [x86_64-darwin11.0]
server -- [2014-12-11 22:56:42] INFO WEBrick::HTTPServer#start: pid=71848 port=9292
server -- 127.0.0.1 - - [11/Dec/2014 22:56:42] "GET /vars HTTP/1.1" 200 110 0.0527
curl -- Uptime:
curl -- 22:56 up 4 days, 12:07, 5 users, load averages: 0.78 0.84 0.76
curl --
curl --
curl -- ESTABLISHED connections:
curl -- 12
curl --
curl --
server -- 127.0.0.1 - - [11/Dec/2014 22:56:43] "GET /vars HTTP/1.1" 200 110 0.0210
curl -- Uptime:
curl -- 22:56 up 4 days, 12:07, 5 users, load averages: 0.78 0.84 0.76
curl --
curl --
curl -- ESTABLISHED connections:
curl -- 12
curl --
curl --
Final remarks
I think there is a lot of potential in the approach from Org mode
for Literate Programming, so it is worth a try.
Take a look at the concepts exposed by Knuth in his paper on the
matter, and you will find out that the core ideas about LP have not
shown its age.
These days, most of my development starts from an Org mode buffer
and it just continues there. With Org mode, you can basically start with a Readme
(c.f. Readme Driven Development), and then just contine doing the
full implementation of your source there in the same place, along with
your notes (but which are not exported).
At the same time, it makes up for very useful documentation for others
to pick up a project later on.
And also Org mode file rendering is supported by Github! In case of bugs,
please send me a ticket here.
08 Dec 2014
Distributed Systems are hard.
As a service grows popular, there inevitably comes the time that capability to scale is demanded from
a system, and while doing so it is required that the system has uptime.
As we go on tackling such issues, it results that we end up with a
distributed system that becomes increasingly complex and its
understanding requires an ongoing online computation of its state.
Under such a system, failures are a constant, and whether this failure
ends up in tragedy or not, depends on how well the platform developer
was prepared for such events.
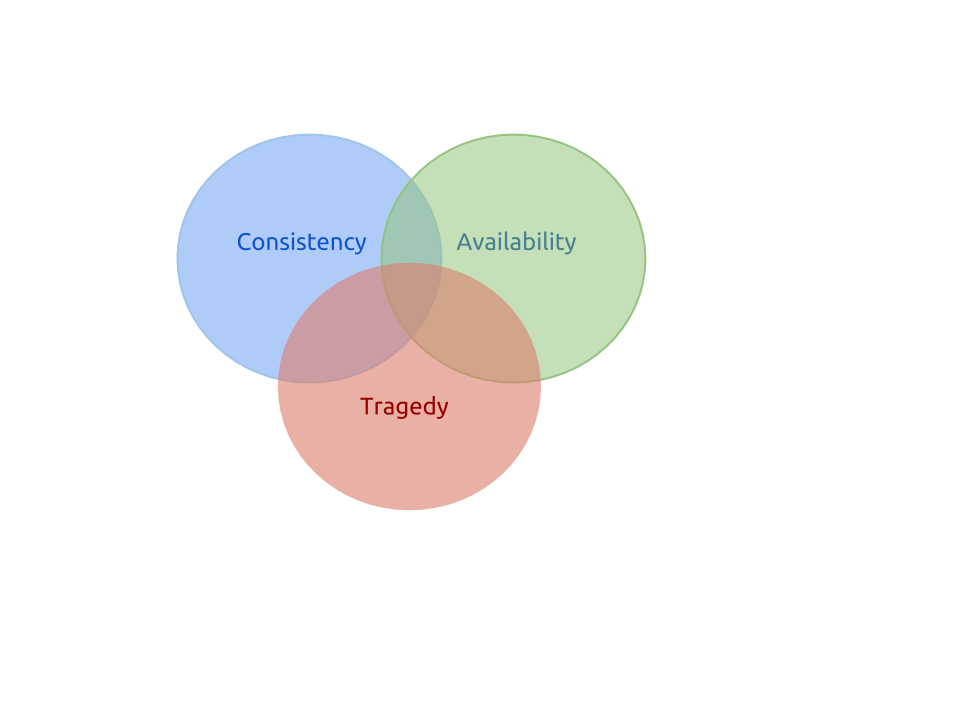
Fig. 1. The CAT theorem (coined by Stan)
Then, what if while at handling this complexity, or a tragic event that ends up in firefighting,
(in your loneliest loneliness as Nietzche puts it),
a demon came up to you and reveal that it doesn’t
get any better? That there is no way around it,
and ”this life which you live must be lived by you once again and innumerable times more; and every pain and joy and thought and sigh must come again to you, all in the same sequence”.
Nietzche poses as the outcome of this thought experiment
one out of two possible choices: the individual either accepts it and becomes stronger
from the cognitive process triggered as a result of the tragedy (amor fati),
or the individual succumbs to what he calls Ressentiment.
The platform developer, by attempting to build and operate a
distributed system, will continuously be exposed to a set of challenges
that will end up with having to face this test of character.
Such as in life (which is itself some sort of distributed system too),
in a distributed system, tragedy is a constant. The CAP theorem & FPL result,
are just a couple of examples which show the constant tragedy that comes
along with operating distributed systems.
For the platform developer that does not succumb to ressentiment, what
lies ahead is easy to predict: it will reflect on the tragedy and use
the literature to improve the situation and in the end, succeed like
others have before in taming a system with many moving parts without
shying away from the difficult problems. Tackling and understanding the
tradeoffs around fault tolerance, high availability, distributed
agreement, etc… all lead to a living a good life for the platform
developer.
But what about the platform developer that succumbs to ressentiment?
Like the quote from Tolstoy goes:
All happy families are alike; each unhappy family is unhappy in its own way.
In my experience (and under my line of reasoning stated in the previous
paragraphs), when such thing happens it could be possible to see some
of the following behaviors below for example:
Cynism, Skepticism
We can avoid having to scale by keeping services small.
Instead of having shared infrastructure we could make everyone in the company run
a similar version of the same, then they have to take care of
running it. There is no need to have a platform even if we have
hundreds of nodes.
This platform developer has experienced the pains of having to operate
a distributed system. Microservices are hard, and maybe unnecessary if
complying to enough trade offs. It is ok to be uncompetitive in
terms of platform related efforts and just keeping it simple.
The platform developer keeps the level of automation such that there
is heavy partitioning and waste in the data center and tries to delegate
difficult issues to avoid tragedies around operating a complex system.
The sysadmin as practitioner of a slave morality
A developer either aware or unaware of the challenges of having to run
a distributed system may try to shield himself/herself of the issue.
As a result of the lack of empathy by the developer,
a platform developer may develop ressentiment towards the opressors,
that is the developers who lack empathy to the problem of tackling
scalability issues.
“Hell is other developers”
Ressentiment is to those that do not understand the situation in the
the data center, and to those heavy users who are causing the architecture
continue to grow.
The problem is not the platform, but the architecture of the application.
Had the application architechture been designed properly there wouldn’t be a need to have as many servers.
Or there could be ressentiment as well to those users who for analytics purposes capture everything and produce lots of data.
In case it is for auditing purposes, ressentiment then is towards those who audit.
The platform developer becomes more used to externalize issues that
could be fixed in the platform on the users rather than fixing them.
Conclusion
It is my believe then that, compared to other areas of software
development, there is a Tragic Sense of Life which
has to be acknowledged earlier on when faced with operating
a distributed system running in production, that is if one is set to the task of doing it correctly.
It is also my believe that even after much tragedy, a platform developer
with ressentiment still has chance to overcome it and attempt to
tackle the core issues of building a distributed system.
It takes start asking “Why?” and then proceed to start reading papers,
looking for someone else that has posed the same question
(many times these fundamental questions already have been answered decades ago…)
Links
Some links that have helped me out learning about distributed systems:
- Distributed Systems for fun and profit
-
I have found this book very useful to immerse in the basics of
working with distributed systems.
http://book.mixu.net/distsys/
- Distributed Systems Archaeology talk by Michael Bernstein
-
Another great talk by a man with an obsession which I can’t
recommend enough.
http://michaelrbernste.in/2013/11/22/distributed-systems-archaeology.html
- Papers we love
-
There are many great distributed systems related videos of the meetups available
http://paperswelove.org/
- A Brief Tour of FLP Impossibility
-
TL;DR;
“it’s not possible to say whether a processor has crashed or is simply taking a long time to respond.”
http://the-paper-trail.org/blog/a-brief-tour-of-flp-impossibility/
- The CAP Theorem
-
Paper itself can be found at Papers we love repo. But
the Distributed Systems for fun and profit book covers it in the
chapter 2 as well.
- Distributed systems theory for the distributed systems engineer
-
Great compilation of links
http://the-paper-trail.org/blog/distributed-systems-theory-for-the-distributed-systems-engineer/
04 Dec 2014
Like most Org mode users, I started using Org mode as a TODO list.
Though for a while now, the Org Babel mode has become an intrinsic
part of my flow as well, to the point that outside doing code reading
of other projects, I rarely visit files anymore and spend most of my
time within Org mode buffers.
In this post I will attempt to document such progression to this style
of using Org mode, and should also serve as a kind of tutorial for
those without familiarity to Org mode.
Basic elements of Org mode
Org mode has a ton of features, so rather than explaining
each one of the features of Org mode, I will describe what
are the building blocks that we can choose from
when authoring an Org mode document.
Some of the most basic elements of an Org mode document are:
- Org mode markup paragraphs
-
Similar to other markup languages, we can write text in /italics/, *bold*,
_underline_, =code= or ~verbatim~, and even super and subscript: n_1, n^2
- headlines and sections
-
A section in Org mode is started by a headline. Headlines start
with one or more asterisks.
* A headline
Paragraph within a /headline/
We can set a TODO state to a headline to define whether something
is done or not:
* TODO Need to do this!
* DONE Needed to do this!
- blocks
-
A block is how we group together a bunch of lines that are not
meant to be only paragraphs. Some of the builtin blocks that we can have
in Org mode are: src, example, verse, quote and html.
A block will start #+begin_... and end with #+end_....
One of the coolest features of the Org mode code blocks is that
we can add metadata to them, such as which kind of language is
being used inside of it (in case of src an example code blocks).
#+begin_src ruby
"Hello world"
#+end_src
In order for syntax highlighting to work, it is needed to include
the following in the Emacs configuration file (or just eval it
during boot):
(setq org-src-fontify-natively t)
It is also required that the Emacs install has the special mode
for it.
- lists
-
A list can be an unordered, ordered or definition list:
- first level
Org mode /markup/
+ second level
1) third level
1. fourth level
- back to first level
+ a definition list ::
some definition
By putting empty brackets [ ], [/], or [%] at the beginning of a list, it
can become a task list. Pressing C-c C-C on an item would
update its value:
Before:
- [0/1] one
+ [ ] two
- [0%] three
* [ ] four
After:
- [1/1] one
+ [X] two
- [100%] three
* [X] four
- tables
-
An Org mode table:
| apples | 10 |
| oranges | 20 |
Tables in Org mode are very powerful. They are not meant to be
only for authoring tables, but they have spreadsheet
functionality as well. The following table would have its formulas
evaluated after pressing TAB on it:
Before:
| fruit | quantity | price per fruit | COST |
| apples | 10 | 5 | =$2 * $3 |
| oranges | 20 | 7 | =$2 * $3 |
| TOTAL | =vsum(@2..@3) | | |
After:
| fruit | quantity | price per fruit | COST |
| apples | 10 | 5 | 50 |
| oranges | 20 | 7 | 140 |
| TOTAL | 30 | | |
#+TBLFM: $2=vsum(@2..@3)::$4=$2 * $3
Basic usage of Org mode for TODO lists
At the beginning of my Org mode usage, my documents used to look like
this I think:
* TODO Reply email from Alice
** TODO Reply
Dear Alice...
* TODO Capacity planning
One of the features I first adopted is the use of CLOCKS.
You can start a clock by pressing: C-c C-x TAB,
then we you are done you clock out with C-c C-x C-o.
Then you can use C-c C-x C-d to check the total time spent.
* DONE Reply email from Alice
CLOCK: [2014-12-04 Thu 15:45]--[2014-12-04 Thu 15:50] => 0:05
,** DONE Reply
CLOCK: [2014-12-04 Thu 16:00]--[2014-12-04 Thu 17:00] => 1:00
Dear Alice...
,* TODO Capacity planning
Another helpful feature is narrowing down to a headline so that
other headlines are not shown. This can be done by pressing C-x n s.
Having covered these basic I’ll go on to talk about Org Babel.
Start using Org mode for reproducible documents
The key thing about when using Org mode and for literate programming
is when you care about making things reproducible.
Eric Schulte paper has more background on how the project started: http://www.jstatsoft.org/v46/i03
In order to use Org Babel we first need to enable it. This is how my
.emacs looks for this:
(setq org-src-fontify-natively t)
(setq org-confirm-babel-evaluate nil)
(org-babel-do-load-languages
'org-babel-load-languages
'((emacs-lisp . t)
(clojure . t)
(R . t)
(C . t)
(sh . t)
(ruby . t)
(python . t)
(js . t)
(dot . t)
(haskell . t)
(scala . t)
))
Note that in order for the above to work, there have to be major modes
in Emacs for those specific languages. Comment out or remove the
language that is not on your setup.
Making the document active by giving things a name
To adopt Org mode literate programming mode, we need to start
using #+name on top of some Org mode elements. By doing this,
it is possible to reference later on to that part of the document.
For example we can have a code block and eval it with C-c C-c:
#+BEGIN_SRC ruby
1 + 1
#+END_SRC
#+RESULTS:
: 2
But by giving it a name, we can reuse this code block:
#+name: sum
#+BEGIN_SRC ruby :var arg1=1 :var arg2=2
arg1 + arg2
#+END_SRC
#+RESULTS:
: 2
#+call: sum(10, 100)
#+RESULTS:
: 110
Or chain it with a table:
#+name: fruits
| apples | 10 |
| oranges | 20 |
#+name: show-fruits
#+BEGIN_SRC ruby :var fruitstable=fruits :results output code
fruits = Hash[fruitstable]
p fruits
#+END_SRC
#+RESULTS: show-fruits
#+BEGIN_SRC ruby
{"apples"=>10, "oranges"=>20}
#+END_SRC
To be continued…